In this guide, we will be exploring how to set up YOLO object detection with the Raspberry Pi AI HAT, and more importantly, learning how to apply this in your Python projects. We will be taking a look at how to install the required hardware and firmware as well as how to set up and use the object detection Python pipelines. The result of this guide will have you equipped with an understanding of this whole setup, as well as three different example scripts we have written. One will "do something" when an object is detected, another when a certain number of objects are detected, and the last when an object is detected in a certain location.
Like most of our other computer vision guides this one is a fun one, so let's get into it!
What You Will Need
To follow along with this guide you will need a:
- Raspberry Pi 5 - A 2GB or larger model will work.
- AI HAT+ Board - This guide will work with both the 13 TOPS and 26 TOPS versions. TOPS is a measurement of how fast an AI accelerator is so you can expect the 26 TOPS version of the AI HAT+ to be about twice as fast. This means that it can run more demanding and powerful models with greater FPS than the 13 TOPS version.
- Pin Extender (dependant) - The AI HAT+ comes with a pin extender for your Pi, but they are usually not long enough to poke fully through the HAT. If you intend to plug hardware into your Pi or use your Pins in any other way, you will need an extender like this to access them.
- Pi Camera Module - We are using the Camera Module V3, but nearly any official camera module will work.
- Camera Adapter Cable - The Pi 5 comes with a different-sized CSI camera cable to previous models and your camera may come with the older wider one so it's worth double-checking. The Camera Module V3 WILL need one. You can also get them in longer lengths like 300mm and 500mm!
- Cooling Solution - For the Pi 5 itself we are using the Active Cooler. While the AI HAT+ can run without a cooler, if you are running it for extended periods of time, a small self-attaching heatsink may be a worthwhile investment. A little bit of cooling may go a long way here.
- Power Supply
- Micro SD Card - At least 16GB in size.
- Monitor and Micro-HDMI to HDMI Cable
- Mouse and Keyboard
Hardware Installation
 Before installing any hardware on your Pi ensure that it is turned off and unplugged from any power source.
Before installing any hardware on your Pi ensure that it is turned off and unplugged from any power source. Install the 4 standoffs that came with your AI HAT. Four long and four short screws come with the standoffs and it doesn't matter which ones are used.
Install the 4 standoffs that came with your AI HAT. Four long and four short screws come with the standoffs and it doesn't matter which ones are used. To install the PCIe cable from the HAT into the Pi start by lifting the brown tab on the Pi's PCIe slot. Insert the cable into the slot and ensure it sits nice and square in there. Push the tab back down to secure it in place.
To install the PCIe cable from the HAT into the Pi start by lifting the brown tab on the Pi's PCIe slot. Insert the cable into the slot and ensure it sits nice and square in there. Push the tab back down to secure it in place.  Now slide the Hat onto the pin extender until it sits flat on the standoffs. Be careful to not damage the PCIe cable in this process.
Now slide the Hat onto the pin extender until it sits flat on the standoffs. Be careful to not damage the PCIe cable in this process.  The connectors for the camera use a similar tab connectors as the PCIe connector. On both the camera and the Pi's connector slot lift the tab, insert the cable so it sits square, and then push the connector back down to secure it in place.
The connectors for the camera use a similar tab connectors as the PCIe connector. On both the camera and the Pi's connector slot lift the tab, insert the cable so it sits square, and then push the connector back down to secure it in place. And finally secure the HAT down with the remaining 4 screws. If you are opting to use a self-adhesive heatsink on the AI HAT, place it on the silver processing unit in the centre of the board.
And finally secure the HAT down with the remaining 4 screws. If you are opting to use a self-adhesive heatsink on the AI HAT, place it on the silver processing unit in the centre of the board.Installing Pi OS
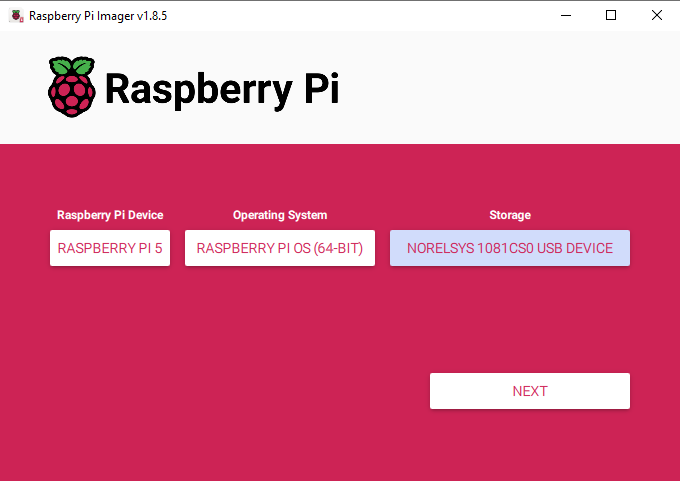
First things first, we need to install Pi OS onto the micro SD card. Using the Raspberry Pi Imager, select Raspberry PI 5 as the Device, Raspberry Pi OS (64-bit) as the Operating system, and your microSD card as the storage device.
NOTE: INSTALLING PI OS ONTO THE MICROSD CARD WILL WIPE ALL DATA ON IT.
This process may take a few minutes to download the OS and install it. Once the process has finished, insert it into the Pi and boot it up. Your Pi will run through a first-time installation and ensure that you connect it to the internet.
Installing AI HAT Software and Python Pipelines
Let's start by installing the required firmware and software to run the AI HAT. Open up a new terminal window and start by updating your Pi with:
sudo apt update && sudo apt full-upgrade
In these steps you may be asked to confirm if you want to install something, just hit "y" and enter.
Now install the HAT firmware with:
sudo apt install hailo-all
This installation may take a good 5 to 10 minutes to complete. Once it has finished restart your Pi. If you want to be a power user you can restart it by typing into the terminal:
reboot

Now we will install Hailo's Python pipeline software and examples, but what is a pipeline?
Communicating with the AI HAT hardware itself is incredibly complicated and the code needed to do that is quite involved. We instead are going to set up and install an object detection pipeline which is just a collection of code and software to allow us to more-easily interact with the hat. It is essentially going to take our simpler and more human-readable code and turn all the gears behind the scenes to get the HAT to run it.
To install the pipeline and required libraries to run it, start by copying their GitHub repository by entering into the terminal:
git clone https://github.com/hailo-ai/hailo-rpi5-examples.git
This will download a folder called "hailo-rpi5-examples" into your Pi's home folder and it is going to be an important location that we will be working in.
Before we install the pipeline we need to tell the terminal to work out of that folder with the change directory command:
cd hailo-rpi5-examples
The blue text with the file location in the terminal shows that you have successfully run this command. Now we will run the shell script installer with:
./install.sh
This installation may take 10 - 20 minutes as it also installs all the YOLO models that we will be using.
Once the installation has finished, restart your Pi once more.

Running Object Detection Demo
Let's run some demo code! In the previous step, we downloaded some sample pipelines from Hailo as well as a sample Python scripts to use these pipelines. We will be using the object detection pipeline in this tutorial - it's called "detection_pipeline.py" and is located under hailo_rpi5-examples/basic_pipelines.
The easiest way to run these Python scripts is through the terminal. First change the terminal's working location with the change directory command, this is the same as the previous one we used:
cd hailo-rpi5-examples
The installation step also created a virtual environment (also called a Venv). This is essentially an isolated virtual workspace we can use to install packages and experiment without the risk of affecting the rest of our Pi OS. All of the packages we need to use were installed in this Venv and we can tell the terminal to enter by typing in:
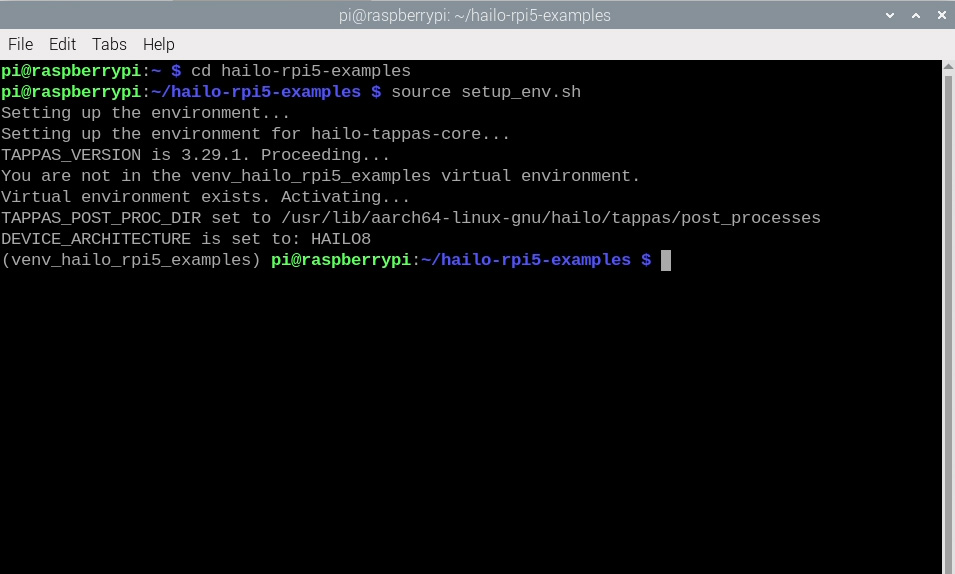
source setup_env.sh
You can confirm that you are working in a Venv as you will see the name of it on the left in brackets as seen in the image on the right. If you have this and the blue text from the change directory command, you are now ready to run the Python scripts. If you ever close the terminal or restart your Pi, you will need to run these commands again to return to this state.
We are going to run the Demo Python code called "detection.py" which is located in the "basic_pipelines" folder, so the command for this will be:
python basic_pipelines/detection.py
You should see a new window appear with a video of people crossing the road as well as the YOLO object detection model identifying objects in the frame as shown in the image on the right. Congratulations! You have successfully set up and run computer vision on your AI HAT.
The visual output of this we are seeing is straightforward. YOLO tries to draw a bounding box around where it thinks the object is, then labels it with what it identified it as and rates the confidence of that detection with a percentage. The default YOLO models are trained on the COCO dataset which only contains 81 detectable objects. This may not seem like a lot, but many of these are broad categories of objects seen in day-to-day life like "sports ball" and "bottle".

To run the Python code with our camera as the input video source, we will need to specify it as an argument or option. We can get a list of all the available options of the object detection pipeline by entering:
python basic_pipelines/detection.py --help
There are a few helpful options here to explore, and you should sometime, but the one we are interested in is changing the source with the "--input" option. Here we can see that we can specify a file or camera as an input and that we can run the detection script with the camera module with:
python basic_pipelines/detection.py --input rpi

Now that we have our code running and detecting objects from our camera, let's take a quick look under the hood and see what's going on so that we can learn how to apply this object detection in our custom projects. There is a lot of complexity going on here and there are thousands of lines of code being run, but most of that is happening behind the scenes in the pipeline. This is fortunate for us as it means that we only have to interact with the "detection.py" file which is far more streamlined and human-readable (we call this high-level code).
Let's open up detection.py in Thonny and explore what's going on. The code starts by importing all the required packages and libraries to run, 2 of these are Python scripts in the same folder, "detection_pipeline" and "hailo_rpi_common". If you wish to modify a deeper behaviour in this setup that is not in detection.py, it will likely be somewhere in these files. If you wish to import any libraries or packages for your project, whack it up here as usual.
import gi
gi.require_version('Gst', '1.0')
from gi.repository import Gst, GLib
import os
import numpy as np
import cv2
import hailo
from hailo_apps_infra.hailo_rpi_common import (
get_caps_from_pad,
get_numpy_from_buffer,
app_callback_class,
)
from hailo_apps_infra.detection_pipeline import GStreamerDetectionApp
Then we have a class defined at the top of the script with a function called "__init__" nested inside of it. Typically when code is written we place the "initialisation" code at the top and it is run once. This class at the top is where we place this "initialisation" code. So if we want to define a constant variable, set up a pin, or declare a function, it must be done in this section. Hailo has provided an example of creating a variable and function in this section:
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
self.new_variable = 42 # New variable example
def new_function(self): # New function example
return "The meaning of life is: "
Then we have a function called "app_callback". The contents of this function will be run every time the AI HAT processes a frame and it can be thought of as the while true loop that we typically use in code. The first dozen or so lines of code in this loop are of little interest to us. They are mostly just managing the pipeline and at the end of it create the object called "detections" that holds all the object detection information coming out of the YOLO model.
def app_callback(pad, info, user_data):
# Get the GstBuffer from the probe info
buffer = info.get_buffer()
# Check if the buffer is valid
if buffer is None:
return Gst.PadProbeReturn.OK
# Using the user_data to count the number of frames
user_data.increment()
string_to_print = f"Frame count: {user_data.get_count()}\n"
# Get the caps from the pad
format, width, height = get_caps_from_pad(pad)
# If the user_data.use_frame is set to True, we can get the video frame from the buffer
frame = None
if user_data.use_frame and format is not None and width is not None and height is not None:
# Get video frame
frame = get_numpy_from_buffer(buffer, format, width, height)
# Get the detections from the buffer
roi = hailo.get_roi_from_buffer(buffer)
detections = roi.get_objects_typed(hailo.HAILO_DETECTION)
Now we get to the meat of this code where we start handling the detections object. Inside this for loop is a series of steps. For every object detected it first gets the label of it (the name of it), the coordinates of the bounding box (the box it draws around the object), and the confidence rating of the detection. These three bits of information are the key puzzle pieces to your project as it is the output of what the camera is seeing. In this demo code it then checks if the detected thing is a person, then increases a counter by 1 and the resulting code counts how many people are in the image (although it doesn't do anything with it).
detection_count = 0
for detection in detections:
label = detection.get_label()
bbox = detection.get_bbox()
confidence = detection.get_confidence()
if label == "person":
string_to_print += f"Detection: {label} {confidence:.2f}\n"
detection_count += 1
The rest of the code uses openCV to display relevant information, and then print the detection data to the shell.
if user_data.use_frame:
# Note: using imshow will not work here, as the callback function is not running in the main thread
# Let's print the detection count to the frame
cv2.putText(frame, f"Detections: {detection_count}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# Example of how to use the new_variable and new_function from the user_data
# Let's print the new_variable and the result of the new_function to the frame
cv2.putText(frame, f"{user_data.new_function()} {user_data.new_variable}", (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# Convert the frame to BGR
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
user_data.set_frame(frame)
print(string_to_print)
return Gst.PadProbeReturn.OK
With this script, you now have the tools to start using the AI HAT for your own object detection projects. This may be enough for some makers, but we have also gone ahead and written three example pieces of code based on detection.py which are a bit more refined and robust. These scripts are designed to allow you to get your project up and running, whilst also giving some more examples of how to modify detections.py for your needs.
Example Code 1: Object Detection
The end goal of this script is to "do something" if we detect a certain object. Here is the entire code:
import gi
gi.require_version('Gst', '1.0')
from gi.repository import Gst, GLib
import os
import numpy as np
import cv2
import hailo
from hailo_apps_infra.hailo_rpi_common import (
get_caps_from_pad,
get_numpy_from_buffer,
app_callback_class,
)
from hailo_apps_infra.detection_pipeline import GStreamerDetectionApp
from gpiozero import AngularServo
# Inheritance from the app_callback_class
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
# Initialize state variables for debouncing
self.detection_counter = 0 # Count consecutive frames with detections
self.no_detection_counter = 0 # Count consecutive frames without detections
# State tracking, is it active or not?
self.is_it_active = False
self.servo = AngularServo(18, min_pulse_width=0.0006, max_pulse_width=0.0023)
def app_callback(pad, info, user_data):
# Get the GstBuffer from the probe info
buffer = info.get_buffer()
# Check if the buffer is valid
if buffer is None:
return Gst.PadProbeReturn.OK
# Using the user_data to count the number of frames
user_data.increment()
# Get the caps from the pad
format, width, height = get_caps_from_pad(pad)
# If the user_data.use_frame is set to True, we can get the video frame from the buffer
frame = None
if user_data.use_frame and format is not None and width is not None and height is not None:
frame = get_numpy_from_buffer(buffer, format, width, height)
# Get the detections from the buffer
roi = hailo.get_roi_from_buffer(buffer)
detections = roi.get_objects_typed(hailo.HAILO_DETECTION)
# Track if we've seen objects of interest this frame
object_detected = False
detection_string = ""
# Parse the detections
for detection in detections:
label = detection.get_label()
confidence = detection.get_confidence()
# Check for objects of interest with confidence threshold
if confidence > 0.4: # Adjust confidence threshold as needed
if label == "person":
object_detected = True
detection_string += f"Detection: {label} {confidence:.2f}\n"
# Debouncing logic
if object_detected:
user_data.detection_counter += 1
user_data.no_detection_counter = 0
# Only activate after given amount of consecutive frames with detections
if user_data.detection_counter >= 4 and not user_data.is_it_active:
# Move the Servo or do what ever you want to do
user_data.servo.angle = 90
# Update the is it active variable so this doesnt keep repeating
user_data.is_it_active = True
print("OBJECT DETECTED!")
else:
user_data.no_detection_counter += 1
user_data.detection_counter = 0
# Only deactivate after 5 consecutive frames without detections
if user_data.no_detection_counter >= 5 and user_data.is_it_active:
# Move the Servo or do what ever you want to do
user_data.servo.angle = 0
user_data.is_it_active = False
print("Object Gone.")
# Print detections if any
if detection_string:
print(detection_string, end='')
return Gst.PadProbeReturn.OK
if __name__ == "__main__":
# Create an instance of the user app callback class
user_data = user_app_callback_class()
app = GStreamerDetectionApp(app_callback, user_data)
app.run()
To run this code, create a new Python file in the same basic_pipelines folder. For this example, we called it "watcher.py". To run the code, it is the same command as before but we must use the new name:
python basic_pipelines/watcher.py --input rpi
This code is currently set up to move a servo if a person is detected and an example of it in action is to solve a real problem in the office. At my desk, I often have my headphones on which makes it easy for people to startle me when they enter the office from behind me. When this code detects a person in the camera pointed at the door behind me, it rotates a servo creating a visual alert that someone has entered!
Let's take a look at some of the essential sections of the code to see what we have added and how you can purpose it for your needs.

We begin by importing the exact same libraries, but with the addition of gpiozero library which has the easy to use servo control we will be using
from gpiozero import AngularServo
Then in the class that runs once, we create a few variables. There are 2 counter variables that we will use for debounce, and a "is_it_active" variable we will use to keep track of the servo's current state. We also set up our servo which connected to pin 18. Very importantly observe that when we create a variable in this section we have to have the "self." prefix. If we want a variable to be accessible from our app_callback() (the "while true loop") we will need to have this prefix.
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
# Initialize state variables for debouncing
self.detection_counter = 0 # Count consecutive frames with detections
self.no_detection_counter = 0 # Count consecutive frames without detections
# State tracking, is it active or not?
self.is_it_active = False
self.servo = AngularServo(18, min_pulse_width=0.0006, max_pulse_width=0.0023)
The first half of the app_callback() is left unchanged as it is managing the pipeline and we don't want to mess with that. After that, we start by creating a variable called "object_detected" and "detection_string". As we are creating them inside the loop, we do not need the "self." prefix, but they will be erased at the end of every cycle of the loop.
# Track if we've seen objects of interest this frame
object_detected = False
detection_string = ""
# Parse the detections
for detection in detections:
label = detection.get_label()
confidence = detection.get_confidence()
# Check for objects of interest with confidence threshold
if confidence > 0.4: # Adjust confidence threshold as needed
if label == "person":
object_detected = True
detection_string += f"Detection: {label} {confidence:.2f}\n"
Then we get to our for detections loop where we cycle through every detected object in the current frame. Here we grab the label and confidence as usual. Then we will check if the confidence is greater than 0.4 (40%), and if it was identified as a person - you can adjust both the confidence rating and the object you are trying to detect to suit your needs. If it is a person and it is confident enough, we set object_detected to true. With this section, we essentially analyse every object the camera has seen and check if at least one of them is a person.
# Parse the detections
for detection in detections:
label = detection.get_label()
confidence = detection.get_confidence()
# Check for objects of interest with confidence threshold
if confidence > 0.4: # Adjust confidence threshold as needed
if label == "person":
object_detected = True
detection_string += f"Detection: {label} {confidence:.2f}\n"
This next section is what truly makes this code robust. If we have detected a person, we increase the detection_counter by 1 and set the no_detection_counter back to 0 as this counter is instead counting how many frames we haven't seen a person. Very importantly observe that when we use detection_counter (which was declared in the class before) we have to have the "user_data." prefix. So when we create a variable above in the class section we use "self." - and when we want to use it here in app_callback() we must have "user_data.".
In the next line, we check if detection_counter is above 4 and if it is, we move the servo (again noting that when we move the servo we have to still use "user_data."). Here you can put your custom code to "do something" if your object is detected. You could send an email, turn on a light, spin a motor, whatever you want!
But why do we count 4 frames in a row before we do something? Well, this is because we are adding something similar to debounce on a button. Let's say this code didn't have this debounce and we used the code to watch outside a house to automatically open the dog door when a dog is detected. Let's say the system works great, but one day a cat approaches the door. Yolo will quite reliably identify it as a cat - but computer vision isn't perfect. For 1 frame it might identify it as a dog by mistake which would open up the dog door when we don't want it to. Most of the time this isn't an issue, but we have found in our testing that there are some outlier cases where this can be quite a bit of an issue.
This debounce code helps remove this issue by ensuring that YOLO detects the target object 4 times in a row before it "does something" and you can change this number to fit the needs of your project.
# Debouncing logic
if object_detected:
user_data.detection_counter += 1
user_data.no_detection_counter = 0
# Only activate after given amount of consecutive frames with detections
if user_data.detection_counter >= 4 and not user_data.is_it_active:
# Move the Servo or do what ever you want to do
user_data.servo.angle = 90
# Update the is it active variable so this doesnt keep repeating
user_data.is_it_active = True
print("OBJECT DETECTED!")
We also have the inverse of all of this. In this else branch (if we don't detect a human), we set detection_counter to 0 and increase no_detection_counter by 1. We then check if no_detection_counter is greater than 5 and if it is, we will move the servo back. Here is where you can put your custom code to "do something else" when the target object isn't detected.
This code needs 5 frames where the object isn't detected before it "does something" and we do it for similar reasons as before. Let's say a dog is walking up to the doggie door and as it is walking through YOLO detects it as a horse for a single frame. This would close the door on the poor dog. So we fix this by ensuring we have 5 frames in a row without the target object so that we can be sure it has disappeared.
It is worth noting that this debounce does make the code less responsive as 4 or 5 frames must pass before we react to an object in frame. The code will most likely be running at 30fps so that is about 1/6 of a second delay. You can set these values to 1 if you want to remove this feature.
There is also one more thing in this section of the code to explore. On the end of these debounce checks we also check the is_it_active variable we made:
if user_data.detection_counter >= 4 and not user_data.is_it_active:
This is essentially ensuring that when we detect a person, we only "do the something" once every time the object is detected. If the object leaves and comes back, it will "do the something" again but only once. Let's say instead of moving the servo, we send an email when we detect a person. With this current set up, if a person is detected it sends one email, and only send another when the person leaves and comes back. But lets say we didnt check this is_it_active variable. The code would detect a human and it would send an email every single time a frame is analysed (30 emails per second.) You can remove this from your code if needed.
Example Code 2: Counting Objects
This script uses the same debounce as the last code but instead of "doing something" we detect an object, we "do something" if a certain number of objects are detected. Here is the entire code:
import gi
gi.require_version('Gst', '1.0')
from gi.repository import Gst, GLib
import os
import numpy as np
import cv2
import hailo
from hailo_apps_infra.hailo_rpi_common import (
get_caps_from_pad,
get_numpy_from_buffer,
app_callback_class,
)
from hailo_apps_infra.detection_pipeline import GStreamerDetectionApp
from gpiozero import LED
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
# Configuration
self.target_object = "cup" # Object type to detect
# Debouncing variables
self.detection_counter = 0 # Consecutive frames with exact match
self.no_detection_counter = 0 # Consecutive frames without match
# State tracking, is it active or not?
self.is_it_active = False
self.green_led = LED(18)
self.red_led = LED(14)
self.red_led.off()
self.green_led.on()
def app_callback(pad, info, user_data):
# Get the GstBuffer from the probe info
buffer = info.get_buffer()
# Check if the buffer is valid
if buffer is None:
return Gst.PadProbeReturn.OK
# Using the user_data to count the number of frames
user_data.increment()
# Get the caps from the pad
format, width, height = get_caps_from_pad(pad)
# If the user_data.use_frame is set to True, we can get the video frame from the buffer
frame = None
if user_data.use_frame and format is not None and width is not None and height is not None:
frame = get_numpy_from_buffer(buffer, format, width, height)
# Get the detections from the buffer
roi = hailo.get_roi_from_buffer(buffer)
detections = roi.get_objects_typed(hailo.HAILO_DETECTION)
# Count objects in this frame
object_count = 0
detection_string = ""
# Parse the detections
for detection in detections:
label = detection.get_label()
confidence = detection.get_confidence()
# Check for target objects with confidence threshold
if confidence > 0.4:
if label == user_data.target_object:
object_count += 1
detection_string += f"{label.capitalize()} detected! Confidence: {confidence:.2f}\n"
# Debouncing logic for number of items
if object_count >= 3:
user_data.detection_counter += 1
user_data.no_detection_counter = 0
# Only activate after sufficient consistent frames
if user_data.detection_counter >= 4 and not user_data.is_it_active:
# Turn on red led, or do what ever else you want to do
user_data.red_led.on()
user_data.green_led.off()
user_data.is_it_active = True
print(f"NUMBER OF OBJECTS DETECTED!")
else:
user_data.no_detection_counter += 1
user_data.detection_counter = 0
# Only deactivate after sufficient non-matching frames
if user_data.no_detection_counter >= 5 and user_data.is_it_active:
# Turn on green LED or what ever else you wish to do
user_data.red_led.off()
user_data.green_led.on()
user_data.is_it_active = False
print(f"No longer detecting number of objects.")
# Print detections if any
if detection_string:
print(f"Current {user_data.target_object} count: {object_count}")
print(detection_string, end='')
return Gst.PadProbeReturn.OK
if __name__ == "__main__":
# Create an instance of the user app callback class
user_data = user_app_callback_class()
app = GStreamerDetectionApp(app_callback, user_data)
app.run()
This code is currently set up to control a pair of LEDs in this tower light - exactly like the previous one. The example application of this one is that we are instead going to set it up as a smart monitoring system. Resin 3d printed parts are toxic until the last curing step and we wish to keep people away from it when it is printing. So this setup will look for persons and if it detects a person and they are located near the printers it will turn on the warning lights.

This code is largely similar to the previous example code with a few additions. First of all we import LED from the gpiozero library which is the easiest way to send digital signals to the GPIO pins.
from gpiozero import LED
Then in the class section, we create a variable for the target object we want to count and in this example, we set it to cups - again change this to whatever you need. We then have the same counting variables as last time. But in this section, we set up our LEDs and initialise the red to be off and the green on. Note how we still have to use the "self." prefix.
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
# Configuration
self.target_object = "cup" # Object type to detect
# Debouncing variables
self.detection_counter = 0 # Consecutive frames with exact match
self.no_detection_counter = 0 # Consecutive frames without match
# State tracking, is it active or not?
self.is_it_active = False
self.green_led = LED(18)
self.red_led = LED(14)
self.red_led.off()
self.green_led.on()
Our code is largely the same till we get to the detection loop. Here for every object with a confidence higher than 0.4 and is labelled as our target_object, we increase the counter by 1.
# Check for target objects with confidence threshold
if confidence > 0.4:
if label == user_data.target_object:
object_count += 1
detection_string += f"{label.capitalize()} detected! Confidence: {confidence:.2f}\n"
Then if there are equal to or more than 3 of those items, we increase the detection counter and run the same debounce code as before and will control the LEDs accordingly using the same logic as the previous code.
# Debouncing logic for number of items
if object_count >= 3:
user_data.detection_counter += 1
user_data.no_detection_counter = 0
# Only activate after sufficient consistent frames
if user_data.detection_counter >= 4 and not user_data.is_it_active:
# Turn on red led, or do what ever else you want to do
user_data.red_led.on()
user_data.green_led.off()
user_data.is_it_active = True
print(f"NUMBER OF OBJECTS DETECTED!")
else:
user_data.no_detection_counter += 1
user_data.detection_counter = 0
# Only deactivate after sufficient non-matching frames
if user_data.no_detection_counter >= 5 and user_data.is_it_active:
# Turn on green LED or what ever else you wish to do
user_data.red_led.off()
user_data.green_led.on()
user_data.is_it_active = False
print(f"No longer detecting number of objects.")
Example Code 3: Object Location
This script uses the same debounce as the previous code snippets, but here we track the centre of the object being detected and we "do something" if it moves into a specified location. Here is the entire code:
import gi
gi.require_version('Gst', '1.0')
from gi.repository import Gst, GLib
import os
import numpy as np
import cv2
import hailo
from hailo_apps_infra.hailo_rpi_common import (
get_caps_from_pad,
get_numpy_from_buffer,
app_callback_class,
)
from hailo_apps_infra.detection_pipeline import GStreamerDetectionApp
from gpiozero import LED
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
# Configuration
self.target_object = "person" # Object type to detect
# Target zone configuration (normalized coordinates 0-1)
self.zone_x_min = 0.4 # Left boundary of target zone
self.zone_x_max = 0.6 # Right boundary of target zone
self.zone_y_min = 0.3 # Top boundary of target zone
self.zone_y_max = 0.7 # Bottom boundary of target zone
# Debouncing variables
self.in_zone_frames = 0 # Consecutive frames with object in zone
self.out_zone_frames = 0 # Consecutive frames without object in zone
# State tracking
self.is_it_active = False
self.green_led = LED(18)
self.red_led = LED(14)
self.red_led.off()
self.green_led.on()
def app_callback(pad, info, user_data):
# Get the GstBuffer from the probe info
buffer = info.get_buffer()
if buffer is None:
return Gst.PadProbeReturn.OK
user_data.increment()
# Get the caps from the pad
format, width, height = get_caps_from_pad(pad)
frame = None
if user_data.use_frame and format is not None and width is not None and height is not None:
frame = get_numpy_from_buffer(buffer, format, width, height)
# Get the detections from the buffer
roi = hailo.get_roi_from_buffer(buffer)
detections = roi.get_objects_typed(hailo.HAILO_DETECTION)
object_in_zone = False
detection_string = ""
# Parse the detections
for detection in detections:
label = detection.get_label()
confidence = detection.get_confidence()
if confidence > 0.4 and label == user_data.target_object:
# Get bounding box coordinates
bbox = detection.get_bbox()
# Call the coordinate methods
x_min = bbox.xmin()
y_min = bbox.ymin()
box_width = bbox.width()
box_height = bbox.height()
# Calculate max coordinates
x_max = x_min + box_width
y_max = y_min + box_height
# Calculate center point (these are normalized 0-1)
center_x = x_min + (box_width / 2)
center_y = (y_min + (box_height / 2) - 0.22) * 1.83
# Debug print for coordinates
detection_string += (f"{label.capitalize()} detected!\n"
f"Position: center=({center_x:.2f}, {center_y:.2f})\n"
f"Bounds: xmin={x_min:.2f}, ymin={y_min:.2f}, xmax={x_max:.2f}, ymax={y_max:.2f}\n"
f"Confidence: {confidence:.2f}\n")
# Check if object's center is in the target zone
if (user_data.zone_x_min <= center_x <= user_data.zone_x_max and
(user_data.zone_y_min - 0.22) * 1.83 <= center_y <= (user_data.zone_y_max - 0.22) * 1.83):
object_in_zone = True
detection_string += f"Object is in target zone!\n"
# Debouncing logic for zone detection
if object_in_zone:
user_data.in_zone_frames += 1
user_data.out_zone_frames = 0
if user_data.in_zone_frames >= 4 and not user_data.is_it_active:
# Turn on red led, or do what ever else you want to do
user_data.red_led.on()
user_data.green_led.off()
user_data.is_it_active = True
print(f"{user_data.target_object.capitalize()} detected in target zone - Servo activated!")
else:
user_data.out_zone_frames += 1
user_data.in_zone_frames = 0
if user_data.out_zone_frames >= 5 and user_data.is_it_active:
user_data.red_led.off()
user_data.green_led.on()
user_data.is_it_active = False
print(f"No {user_data.target_object} in target zone - Servo deactivated!")
# Print detections if any
if detection_string:
print(detection_string, end='')
return Gst.PadProbeReturn.OK
if __name__ == "__main__":
user_data = user_app_callback_class()
app = GStreamerDetectionApp(app_callback, user_data)
app.run()
This code is currently set up to control a pair of LEDs in this tower light. Another practical solution to a problem - each time I get up and grab a drink I often bring back a new cup and they start to crowd my desk. This code will detect if there are 3 or more cups on my desk and turn on the red light when there is. If there are less than 3 cups it will turn on a green light.

We start with the same class setup section as before but with some additional variables to draw a box on the image with minimum and maximum x and y values. If the object is inside of this box we will "do something". The box is defined by decimals with 0 on the x-axis being the left side of the image, 1.0 being the right side of the image, and 0.5 being the middle. The y-axis spans from 0 being the top and 1.0 being the bottom. Below is an example of two boxes that can be drawn and you can change these x and y min and max variables to set your custom detection boxes.
The detection_counter variables have also been changed to in_zone_frames and out_zone_frames. This is just a name change and are used exactly the same.
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
# Configuration
self.target_object = "person" # Object type to detect
# Target zone configuration (normalized coordinates 0-1)
self.zone_x_min = 0.4 # Left boundary of target zone
self.zone_x_max = 0.6 # Right boundary of target zone
self.zone_y_min = 0.3 # Top boundary of target zone
self.zone_y_max = 0.7 # Bottom boundary of target zone
# Debouncing variables
self.in_zone_frames = 0 # Consecutive frames with object in zone
self.out_zone_frames = 0 # Consecutive frames without object in zone
# State tracking
self.is_it_active = False
self.green_led = LED(18)
self.red_led = LED(14)
self.red_led.off()
self.green_led.on()


The rest of the code is nearly the same but in our detection loop if the label is target_object and confidence above 0.4 we get the bounding box from YOLO, find the centre of it, and then check if its within our min and max x and y values. If it is, then we set object_in_zone to true and run the same debounce logic exactly the same as the previous 2 code snippets.
if confidence > 0.4 and label == user_data.target_object:
# Get bounding box coordinates
bbox = detection.get_bbox()
# Call the coordinate methods
x_min = bbox.xmin()
y_min = bbox.ymin()
box_width = bbox.width()
box_height = bbox.height()
# Calculate max coordinates
x_max = x_min + box_width
y_max = y_min + box_height
# Calculate center point (these are normalized 0-1)
center_x = x_min + (box_width / 2)
center_y = (y_min + (box_height / 2) - 0.22) * 1.83
# Debug print for coordinates
detection_string += (f"{label.capitalize()} detected!\n"
f"Position: center=({center_x:.2f}, {center_y:.2f})\n"
f"Bounds: xmin={x_min:.2f}, ymin={y_min:.2f}, xmax={x_max:.2f}, ymax={y_max:.2f}\n"
f"Confidence: {confidence:.2f}\n")
# Check if object's center is in the target zone
if (user_data.zone_x_min <= center_x <= user_data.zone_x_max and
(user_data.zone_y_min - 0.22) * 1.83 <= center_y <= (user_data.zone_y_max - 0.22) * 1.83):
object_in_zone = True
detection_string += f"Object is in target zone!\n"
Running Other YOLO Models
Why would we choose another model? Well YOLO comes in many variations across different YOLO versions and model sizes. Newer YOLO models are often more powerful with less processing needs and in the future, you may find YOLO11 as well as other new models here, but the main reason would be to change model size. YOLO comes in 5 sizes - nano, small, medium, large and extra large. The larger the model, the more processing power, accuracy and greater detection distances it has at the cost of FPS. By default, the 13 TOP will run the small model, and the 26 TOP will run the medium model, both of which give a smooth 30 FPS.
The AI HAT+ can run a large selection of neural network models but there is one catch - it must be converted to the HEF format first and it needs to be converted for the specific model hat (one converted for the 13 TOPS hat might not fair so well on the 26 TOPS). There is a process to convert a model to the HEF format and Hailo has a guide on how to do so, but be warned, it is a quite involved process. It can also be an extremely lengthy process as even equipped with the highest-end GPU it can take several hours, with a lower-end or even a CPU this could take days or weeks to convert.
But thankfully we can get pre-converted models from around the internet with one of the best being from Hailo's model zoo. There is a collection of models for the 13 TOPS (Hailo-8) and the 26 TOPS (Hailo-8L) Hats. While several models can be used, we will be focusing on the YOLO family as we have found that the pipeline is more likely to work with them.
To run a model, simply download the compiled version of it which should be on the far right of the table (you may need to scroll to the right to see it). Double-check that you have the ".hef" version of the file. Once you have downloaded it, drag it into the resources folder in the hailo-rpi5-examples folder with the other YOLO models, in our example we downloaded the large model called "yolov8l.hef".
If it is in the folder, you can run the model by adding it as an option in the run command and you will need to use the name of the model. For example, ours will be:
python basic_pipelines/detection.py --input rpi --hef resources/yolov8l.hef
If you attain other YOLO models that have been converted to the HEF format, it will be the same process.
Where to From Here?
We now have a Raspberry Pi and AI HAT setup and running object detection with a few example codes that can be purposed for your project. Now the only thing left to do is to figure out how to do the "something" you want your project to do. We have a few general guides for the Pi to get you started, for example, how to control DC and stepper motors, servos, or even solenoids with a relay (and you can use a relay to control pretty much anything).
If you make something cool with this, have questions about any of this, or just need a hand, feel free to post in the forum topic at the bottom of this page - there is an army of makers over there that are happy to help out. Until next time, happy making!