Have you ever wanted to dive into computer vision? How about on a low-power and portable piece of hardware like a Raspberry Pi?
Well, in this guide we will be setting up some with the YOLO vision model family, OpenCV and the COCO object library on the Raspberry Pi 5. We will be taking a look at a few of the different YOLO models available, how to optimise them for both processing power and speed, how to control hardware with the detection results, and we will also be taking a look at YOLO World, an extremely exciting open-vocabulary model that detects objects from a prompt instead of its pre-trained item list.
Computer vision is now easier and more efficient than ever with us now being able to run high-performance vision models on hardware like the Raspberry Pi. This is thanks to the works of the incredible open-source projects we will be utilising in this guide; the COCO library, OpenCV and YOLO. Before we dive into all of this though, we will be referring to these a lot so a quick analogy is in order to explain their roles.
OpenCV is like a kitchen for our computer vision cook. It provides the necessary tools and framework for us to prepare and make food. YOLO is the cook in the kitchen. It is part of this system that is doing the actual work, "thinking" and trying to identify objects. And lastly, we have the COCO library. This is the training data that YOLO comes with - it's like the cookbook or the recipes that YOLO will follow. If the COCO library has instructions on how to identify a car, YOLO the cook can identify a car, if it doesn't have those instructions, YOLO can't identify it. So YOLO the cook, does work according to the COCO library cookbook in the OpenCV kitchen.
Hopefully that made sense, lets get right into it!
Contents
- What You Will Need
- Hardware Assembly
- Installing Pi OS
- Setting up the Virtual Environment and Installing YOLO
- Running YOLOv8
- Running Other YOLO Models
- Increasing Processing Speed (NCNN Conversion and Resolution)
- Controlling Hardware
- Diving Into YOLO World
- Where to From Here
- Acknowledgements
- Appendix: Using a Webcam
What You Will Need
To follow along with this guide you will need a:
- Raspberry Pi 5 - Either a 4GB or 8GB model will work here. Although this could technically be done on a Pi 4, it is far slower than the Pi 5 and would not be a nice experience, and for those reasons, we haven't tested on a Pi 4
- Pi Camera - We are using the Camera Module V3
- Adapter Cable - The Pi 5 comes with a different-sized CSI camera cable and your camera may come with the older thicker one so it's worth double-checking. The Camera Module V3 WILL need one
- Cooling Solution - We are using the active cooler (computer vision will really push your Pi to its limits).
- Power Supply
- Micro SD Card - At least 16GB in size
- Monitor and Micro-HDMI to HDMI Cable
- Mouse and Keyboard
Hardware Assembly
In terms of hardware assembly, it's pretty light here. Connect the thicker side of the cable to the camera, and the thinner side to the Pi 5. These connectors have a tab on them - lift them up, then insert the cable into the slot. Once it is sitting in there nice and square, push the tab back down to clamp the cable into place.
Just keep an eye out as these connectors only work in one orientation, and they can be fragile so avoid bending them tightly (a little bit is okay).

Installing Pi OS
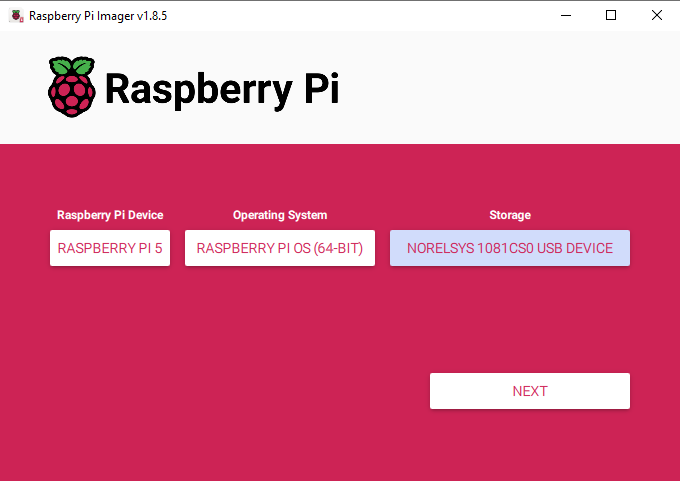
First things first, we need to install Pi OS onto the micro SD card. Using the Raspberry Pi Imager, select Raspberry PI 5 as the Device, Raspberry Pi OS (64-bit) as the Operating system, and your microSD card as the storage device.
NOTE: INSTALLING PI OS ONTO THE MICROSD CARD WILL WIPE ALL DATA ON IT.
This process may take a few minutes to download the OS and install it. Once the process has finished, insert it into the Pi and boot it up. Your Pi will run through a first-time installation and just ensure that you connect it to the internet.
You will also need to remember the username you create here as it will be part of the file locations we cover in this guide. For simplicity's sake you can simply call it "pi".
Setting up the Virtual Environment and Installing YOLO
With the introduction of Bookworm OS in 2023, we are now required to use Virtual Environments (or venv). These are just isolated virtual spaces that we can use to run our projects without the risk of breaking the rest of Pi OS and our packages - in other words, we can do whatever we want here without the risk of damaging the rest of Pi OS. It is an extra moving part to learn, but it's incredibly easy.
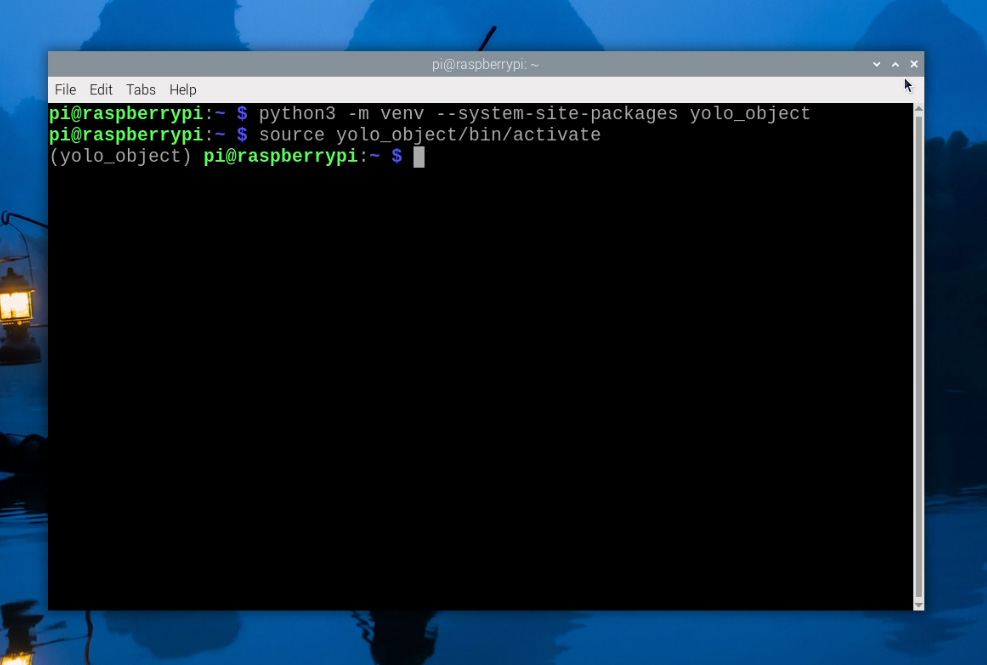
To create a virtual environment, open a new terminal window and type in:
python3 -m venv --system-site-packages yolo_object
This will create a new virtual environment called "yolo_object". You can find the folder of this virtual environment under home/pi and it will be called "yolo_object".
After creating the venv, enter into it by typing in:
source yolo_object/bin/activate
After doing so you will see the name on the virtual environment to the left of the green text - this means we are correctly working within it. If you ever need to re-enter this environment (for example if you close the terminal window you will exit the environment), just type in the source command above again.
Now that we are working in a virtual environment, we can start installing the required packages. First, ensure that PIP (the Python package manager) is up to date by entering the three following lines:
sudo apt update
sudo apt install python3-pip -y
pip install -U pip
Then install the Ultralytics Package with:
pip install ultralytics[export]
The lovely folks at Ultralytics have been one of the key developers and maintainers of the newest YOLO models. This package of theirs is going to do much of the heavy lifting and will install OpenCV as well as all the required infrastructure for us to run YOLO.
This process will also install quite a large amount of other packages, and as a result, is prone to failing. If your installation fails (it will display a whole wall of red text), just type in the Ultralytics install line again and it should resume. In rare cases, the install line may need to be repeated a few times.
Once that has finished installing, reboot the Raspberry Pi. If you want to be a power user, you can do so by typing into the shell:
reboot

We have one more thing to do, and that is to set up Thonny to use the virtual environment we just created. Thonny is the program we will be running all of our code out of and we need to get it to work out of the same venv so that it has access to the libraries we installed.
The first time you open Thonny it may be in the simplified mode, and you will see a "switch to regular mode" in the top right. If this is present click it and restart Thonny by closing it.
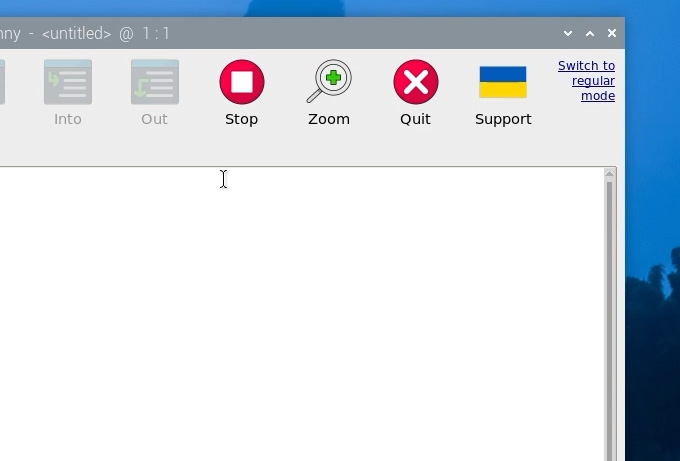
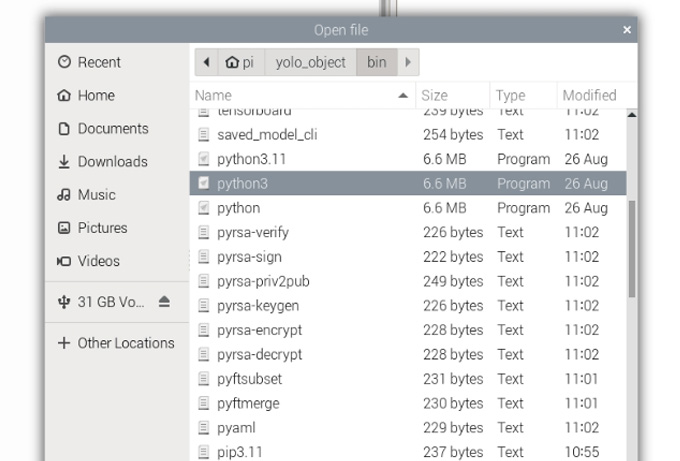
Now enter the interpreter options menu by selecting Run > Configure Interpreter. Under the Python executable option, there is a button with 3 dots. Select it and navigate to the Python executable in the virtual environment we just created.
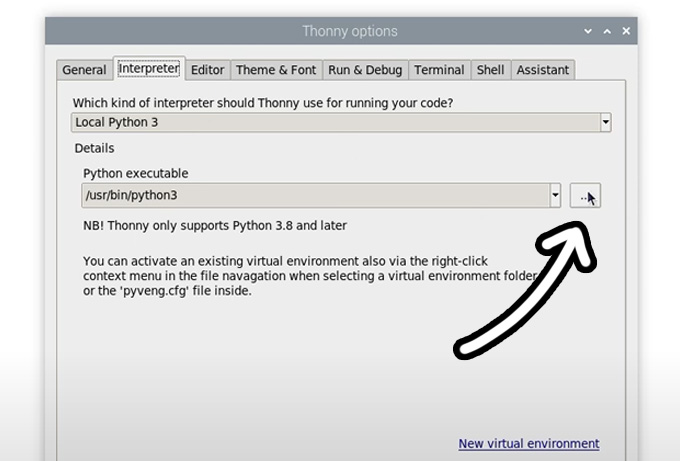
This will be located under home/pi/yolo_object/bin and in this file, you will need to select the file called "python3". Hit okay and you will now be working in this venv.
Whenever you open Thonny, it will now automatically work out of this environment. You can change the environment you are working out of by selecting it from the drop-down menu under the Python executable in the same interpreter options menu. If you wish to exit the virtual environment, select the option bin/python3.
Running YOLOv8
Create a new script in Thonny and paste in the following code:
import cv2
from picamera2 import Picamera2
from ultralytics import YOLO
# Set up the camera with Picam
picam2 = Picamera2()
picam2.preview_configuration.main.size = (1280, 1280)
picam2.preview_configuration.main.format = "RGB888"
picam2.preview_configuration.align()
picam2.configure("preview")
picam2.start()
# Load YOLOv8
model = YOLO("yolov8n.pt")
while True:
# Capture a frame from the camera
frame = picam2.capture_array()
# Run YOLO model on the captured frame and store the results
results = model(frame)
# Output the visual detection data, we will draw this on our camera preview window
annotated_frame = results[0].plot()
# Get inference time
inference_time = results[0].speed['inference']
fps = 1000 / inference_time # Convert to milliseconds
text = f'FPS: {fps:.1f}'
# Define font and position
font = cv2.FONT_HERSHEY_SIMPLEX
text_size = cv2.getTextSize(text, font, 1, 2)[0]
text_x = annotated_frame.shape[1] - text_size[0] - 10 # 10 pixels from the right
text_y = text_size[1] + 10 # 10 pixels from the top
# Draw the text on the annotated frame
cv2.putText(annotated_frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2, cv2.LINE_AA)
# Display the resulting frame
cv2.imshow("Camera", annotated_frame)
# Exit the program if q is pressed
if cv2.waitKey(1) == ord("q"):
break
# Close all windows
cv2.destroyAllWindows()
Running YOLO code will often involve downloading models which will save to the same location that the script is in, so it may be a smart move to create a folder and save your script in there to keep everything neat. We just created a folder on our desktop and saved everything to that. When you save your YOLO code, also ensure that you save it as a ".py" python file.

Now run the code by hitting the green play button, and after a short period of downloading the model, a window should appear showing your camera feed, as well as anything detected by YOLO.
It will automatically draw a box around anything detected, label it, and give a rating of how confident it is on that detection (with 1.0 being the greatest).
And this is our base-level YOLO model working! It may not be the best FPS right now (you should expect about 1.5 FPS), but we will look at how to improve this very soon.
To stop this script, all you need to do is hit the Q key.

Lets quickly take a general look at how this code works so we can somewhat understand whats goin on under the hood.
Starting off, we import the required libraries; cv2 is OpenCV, Picamera2 is the library we use to get the video feed from the camera into our code, and Ultralytics where our YOLO model comes from
import cv2 from picamera2 import Picamera2 from ultralytics import YOLO
Then we end our set up phase by initialising the camera with Picamera2 and loading the YOLOv8 model.
# Set up the camera with Picam
picam2 = Picamera2()
picam2.preview_configuration.main.size = (1280, 1280)
picam2.preview_configuration.main.format = "RGB888"
picam2.preview_configuration.align()
picam2.configure("preview")
picam2.start()
# Load YOLOv8
model = YOLO("yolov8n.pt")
Next we enter into a looping While True loop that gets an image from the camera, feeds it into the YOLOv8 model, and then gets the data it outputs.
while True:
# Capture a frame from the camera
frame = picam2.capture_array()
# Run YOLO model on the captured frame and store the results
results = model(frame)
# Output the visual detection data, we will draw this on our camera preview window
annotated_frame = results[0].plot()
This next bit of code is just some math to calculate the FPS we are processing at, and then some OpenCV related code to attach the FPS to the output data from the model.
# Get inference time
inference_time = results[0].speed['inference']
fps = 1000 / inference_time # Convert to milliseconds
text = f'FPS: {fps:.1f}'
# Define font and position
font = cv2.FONT_HERSHEY_SIMPLEX
text_size = cv2.getTextSize(text, font, 1, 2)[0]
text_x = annotated_frame.shape[1] - text_size[0] - 10 # 10 pixels from the right
text_y = text_size[1] + 10 # 10 pixels from the top
# Draw the text on the annotated frame
cv2.putText(annotated_frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2, cv2.LINE_AA)
Then finally we display the overlay the output data and FPS counter over the camera feed window.
# Display the resulting frame
cv2.imshow("Camera", annotated_frame)
And we end it by letting us press "q" to exit. If the key is pressed, then it will break which will exit out of the current while true loop and close all the windows.
# Exit the program if q is pressed
if cv2.waitKey(1) == ord("q"):
break
# Close all windows
cv2.destroyAllWindows()
Before we move on to improving YOLO, there is a limitation worth pointing out. Right now your Pi is probably able to detect a person sitting in front of it, as well as common things like chairs, TVs, and cups. However, it is not able to detect everything. In the picture on the right, there are many things that aren't being detected and that is because of the limitations in the COCO library.
YOLOv8 has been trained on the COCO library which categorises objects into about 88 different categories - meaning there are only 88 different types of things you can detect. This might not sound like a lot, but when you consider how common and broad some of these categories are like "car" or "sportsball", it amounts to quite a lot it can detect. However, if an object is not part of its training library (like glasses), it won't be able to recognise it. This is a foreshadowing of YOLO World which is going to allow us to get around this limitation.

Running Other YOLO Models
So far we have been running YOLOv8, and one of the beauties of this ultralytics package is that we can simply swap out a single line in the code to completely change the model, and we can use this to run a more advanced v8 model, or even an older model. All you need to change is this line here in the setup:
# Load YOLOv8
model = YOLO("yolov8n.pt")
This line is currently using the nano model which is the smallest, least powerful, but fastest model of YOLOv8, and we can change this line to run one of the different sizes that this model comes in by changing the single letter after "v8" as shown on the right. If you change this line to another model size and run it, the script will automatically download the new model (which can be in the 100s of Mb for the larger models).

As you may have guessed, there is a trade-off here between image processing performance and FPS. If you run the extra-large model, you should be running at less than 0.1 FPS (we will improve this shortly), but you should also notice a great jump in detection performance. These larger models are better at recognising items that are far away from the camera, as demonstrated in the image on the right, and are also better at more reliably recognising objects with greater accuracy. If you hold a cup in your hand, the nano model may jump between recognising it as a phone and a cup, but the extra-large model will more consistently recognise it as a cup.
In our kitchen analogy, this is like telling the cook (YOLOv8), how long should they spend preparing a dish, nano is the least amount of time which may produce some rougher results, and extra-large is a "spend all the time in the world" situation.
There are also different-sized models between these we can use that are at different levels of this processing performance and FPS trade-off so have a play around and see which one is accurate and fast enough for your needs.
One more thing we can change is the model version. YOLO started at v1 and has now made its way up to v10 (we are using v8 though as at the time of writing it was just as fast as 10 and could be optimised better for the Pi). These versions have improved both the speed and capabilities of the models and in our kitchen analogy is like using a more skilled and experienced cook.
Changing this version is just as easy and if for example, we wanted to use v5 for legacy reasons, we would just modify the same line to be:
# Load YOLOv8
model = YOLO("yolov5n.pt")
If you want to try v10, you would just write:
# Load YOLOv8
model = YOLO("yolov10n.pt")
This guide will eventually be outdated, but there is a good chance that if version 11 or 12 or whatever number is released after this guide is published, you should be able to use this same code to run that newest model by simply altering that line.
Update: The day we released this Ultralytics released YOLO11. To use the new model simply alter the line to the following. Note that it appears they have dropped the "V" naming scheme.
# Load our YOLO11 model
model = YOLO("yolo11n.pt")

Increasing Processing Speed
There are 2 things we can do to increase FPS on the Pi and the most effective way is to convert the model to a format called NCNN. This is a model format more optimised to run on ARM-based processors like the Raspberry Pi's. Open up the script called "ncnn conversion.py" and you will find the following:
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
model = YOLO("yolov8n.pt")
# Export the model to NCNN format
model.export(format="ncnn", imgsz=640) # creates 'yolov8n_ncnn_model'
To use this script, first specify the model you wish to convert. This uses the same naming conventions we talked about in the last section. Then the model format "ncnn" is specified as the output format, as well as the resolution. For now keep this at the default of 640. The first time you run this script it will download some more additional things it needs, but it should only take a few seconds to run the actual conversion.
Once that has finished, in the folder the scripts live in your will find a new folder called something along the lines of "yolov8n_ncnn_model". Copy the name of this file and return to our demo script from earlier.
You now need to tell the script to use this model that we created by changing the model line to the name of that folder it just created. It should look something like this:
# Load our YOLOv8 model
model = YOLO("yolov8n_ncnn_model")
And if you run the script, it should work exactly as before but with a 4x increase in FPS thanks to that NCNN conversion.
The other thing we can do to increase FPS is to drop the processing resolution. This is the resolution that we will run the YOLO model at and less pixels means less time spent processing each frame.
While converting to NCNN was a free FPS boost, lowering the resolution does come at the cost of capability. A lower resolution will slightly decrease the accuracy of your pose estimation (not very much though), and the biggest effect it will have is that it decreases the distance it can estimate pose at. With the default resolution of 640, the range is quite far, so we can afford to drop it down a bit.
To do so, open up the NCNN conversion script we just used and specify the resolution to what you want in the line:
# Export the model to NCNN format model.export(format="ncnn", imgsz=320) # creates 'yolov8_ncnn_model'
NOTE: This will need to be a multiple of 32. So you cannot set it to 300, but you can set it to 320.
We find that resolutions in the 160 to 320 range give a good balance of performance and speed.
Run the conversion code and it will export the model with the desired resolution. Doing so will also overwrite any previously exported models of the same name.
In the demo script ensure that you specify the NCNN model like we did before. There is one more important thing we must do and that is to tell the script what resolution to feed the model. In the while true loop, you will find the following line. Ensure that it matches the resolution of the model, for this example we exported at 320:
# Run YOLO model on the captured frame and store the results
results = model.predict(frame, imgsz = 320)
If all goes well, you should see another significant increase in FPS. Play around with this resolution to fit your needs but remember:
- It must be a multiple of 32
- You must change the name in the main script to use the exported model
- You must set the resolution in the main script to match the model

Controlling Hardware
Right now we can identify objects, and optimise that process for our needs, but how do we use it - we only have a preview window of our camera with our detections being overlayed.
All of this data is being retrieved from the results variable. If you run your script for a few seconds and stop it with "q" so that there are a few entries in the shell like in the image on the right, you can type into the shell:
results[0]
You will be able to see the insides of the detection results. The "[0]" on the end means you are getting the results from the newest frame that was analysed. If you scroll through this you should be able to see a section called names containing all of the objects that can be detected by the COCO library as well as the ID associated with these objects (for example, a person is 0, a bicycle is 1, a car is 2 etc). If you want to manually get this list you can type in:
results[0].names

In this results[0] we can also get a list of everything that was detected on screen. If you type in:
results[0].boxes.cls
You will get a list of all the ID's of the objects being detected. In my example on the right, we are only detecting a person which has an ID of 0. This is going to be our main method of utilising our detection results.

Using this "results[0].boxes.cls", we can write code to control hardware with the Raspberry Pi. Here is some demo code that achieves that:
import cv2
from picamera2 import Picamera2
from ultralytics import YOLO
from gpiozero import LED
# Initialize the camera
picam2 = Picamera2()
picam2.preview_configuration.main.size = (1280, 1280)
picam2.preview_configuration.main.format = "RGB888"
picam2.preview_configuration.align()
picam2.configure("preview")
picam2.start()
# initialise output pin
output = LED(14)
# Load the YOLO model
model = YOLO("yolov8n.pt")
# List of class IDs we want to detect
objects_to_detect = [0, 73] # You can modify this list
while True:
# Capture a frame from the camera
frame = picam2.capture_array()
# Run object detection on the frame
results = model(frame, imgsz = 160)
# Get the classes of detected objects
detected_objects = results[0].boxes.cls.tolist()
# Check if any of our specified objects are detected
object_found = False
for obj_id in objects_to_detect:
if obj_id in detected_objects:
object_found = True
print(f"Detected object with ID {obj_id}!")
# Control the Pin based on detection
if object_found:
output.on() # Turn on Pin
print("Pin turned on!")
else:
output.off() # Turn off Pin
print("Pi turned off!")
# Display the frame with detection results
annotated_frame = results[0].plot()
cv2.imshow("Object Detection", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) == ord("q"):
break
# Clean up
cv2.destroyAllWindows()
This code is the same as our previous scripts with a few additions. First we import the libraries required to control the Raspberry Pi's pins, and set up pin 14 with the lines:
from gpiozero import LED # initialise output pin output = LED(14)
Then we define the ID's of the objects we wish to control the pin with. If either of these are present then the pin will turn on. Right now it has 0 - person and 73 - book. You can change these to which ever IDs you want, or add more by simply adding another ID seperated by a comma:
# List of class IDs we want to detect objects_to_detect = [0, 73] # You can modify this list
Then we get the list of detected objects and see if any of the IDs we specify in the previous line match what is being detected in this frame:
# Get the classes of detected objects
detected_objects = results[0].boxes.cls.tolist()
# Check if any of our specified objects are detected
object_found = False
for obj_id in objects_to_detect:
if obj_id in detected_objects:
object_found = True
print(f"Detected object with ID {obj_id}!")
And finally we control Pin 14 and set it on or off if an object is found:
# Control the Pin based on detection
if object_found:
output.on() # Turn on Pin
print("Pin turned on!")
else:
output.off() # Turn off Pin
print("Pi turned off!")
And from here, we can do whatever we want with this. You could control a solenoid like we do in the video guide, or you could control a servo, or motor.
Diving Into YOLO World
YOLO World is an object recognition model that is so incredibly powerful that it deserves its entire section. Usually, models are built upon a library of training data. The COCO library that YOLOv8 uses has been trained to identify cats, so it can do so. But it wasn't trained to identify glasses, so no matter how clearly you show the camera, it will not identify it. The usual way to get it to recognise glasses would be to retrain it and this involved a lengthy and processing-intensive process (far too much of a load for our little Pi), where you would label and feed it images of glasses. And only after this whole process would YOLOv8 be able to detect glasses.
This is the brilliance of YOLO World, it's an open vocabulary model meaning that you describe or prompt it for something to look for and it tries its best to find it. So you can simply tell it to look for glasses and as you can see in the image on the right, it was able to detect them, even without the need for retraining.
This isn't a magical silver bullet that can identify everything though, it still has a limited set of training data to work off, but long story short it has learnt from the whole image itself, not just learning to identify 1 object in that image. So if it is a common object that might appear commonly in photos - things like cameras, glasses, pens, batteries etc - it will most likely be able to detect them. For more obscure things that aren't photographed frequently - things like abacuses and Geiger counters - chances are it wont be able to recognise them.
It also may have some issues detecting common things, we couldn't get it to detect a paintbrush, or keys for example.

To use YOLO World we will need to modify our script slightly, here is some demo code for that:
import cv2
from picamera2 import Picamera2
from ultralytics import YOLO
# Set up the camera with Picam
picam2 = Picamera2()
picam2.preview_configuration.main.size = (1280, 1280)
picam2.preview_configuration.main.format = "RGB888"
picam2.preview_configuration.align()
picam2.configure("preview")
picam2.start()
# Load our YOLOv8 model
model = YOLO("yolov8s-world.pt")
# Define custom classes
model.set_classes(["person", "glasses"])
while True:
# Capture a frame from the camera
frame = picam2.capture_array()
# Run YOLO model on the captured frame and store the results
results = model(frame, imgsz = 640)
# Output the visual detection data, we will draw this on our camera preview window
annotated_frame = results[0].plot()
# Get inference time
inference_time = results[0].speed['inference']
fps = 1000 / inference_time # Convert to milliseconds
text = f'FPS: {fps:.1f}'
# Define font and position
font = cv2.FONT_HERSHEY_SIMPLEX
text_size = cv2.getTextSize(text, font, 1,2)[0]
text_x = annotated_frame.shape[1] - text_size[0] - 10 # 10 pixels from the right
text_y = text_size[1] + 10 # 10 pixels from the top
# Draw the text on the annotated frame
cv2.putText(annotated_frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2, cv2.LINE_AA)
# Display the resulting frame
cv2.imshow("Camera", annotated_frame)
# Exit the program if q is pressed
if cv2.waitKey(1) == ord("q"):
break
# Close all windows
cv2.destroyAllWindows()
Note: The first time you run this script, it may take a few minutes as the YOLO World models are larger and it will download additional required packages - about 400 Mb total.
Right now this script is looking for the words "glasses" and "person", but we can instantly change that by altering this line. All you need to do is put the object you are looking for in quotation marks and separate it with a comma:
# Define custom classes model.set_classes(["person", "glasses", "yellow lego man head"])
In this line above we have used another cool feature of YOLO World and prompted it with a description instead of a single word. And as you can see on the right, it is detecting our yellow Lego man head. The detection is a little hit-and-miss and it is probably identifies the yellow more than anything, but it's a cool example of what can be achieved.
A few things regarding YOLO World though. First of all, it will only detect what you specify in the line above. If you do not describe an object in that list, it will not recognise it. If you delete the entire line, it will look for everything it can though and behave more like YOLOv8.
It also only comes in 3 sizes - small, medium and large - the demo script above it for the small, and you can replace it with the medium or large model by swapping out the s for an m or l. If you wanted the large model you would write:
# Load our YOLOv8 model
model = YOLO("yolov8l-world.pt")
It also can't be converted to NCNN. This is a bit of a shame, but we can at least still drop the resolution to increase performance. And you may need to do so as it will run much slower than the default YOLOv8 model.
All in all, give YOLO World a go for your project. The ability to detect custom objects, or objects based on a prompt offers a great deal of flexibility and customisation. At the very least its a good bit of a fun though.

Where to From Here?
By now we should have YOLO object detection running on our Pi, whether thats YOLOv8, v5 or YOLO World. This guide is just a starting point though and we hope that you get out there are start adding computer vision to your projects. But most importantly, we hope you learnt something and had fun in the process.
If you are looking for some extension work or paths to wander down, have a look inside of the results variable, you can find a whole heap of cool things like the xy coordinates of the boxes being drawn. It is very possible to find the centre of the object being detected from this and wire up a servo to track the object.
If you are looking to run this system for extended periods of time, it will run a lot of read and write cycles on your MicroSD card, so setting up an NVME SDD for longevity may be a beneficial move. We have a great beginner guide on how to do that.
If you want to dive deeper into YOLO, check out the Ultralytics documentation page. They have a whole range of other cool models to check out, and because we have already set up the required infrastructure to use their models, it should be as simple as copying and pasting a demo code that you find there!
Acknowledgements
We would like to first of all thank the many contributors, developers and maintainers of the OpenCV and the COCO library. Much of the modern computer vision world has been built upon their efforts.
We would also like to thank Joseph Redmon and Ultralytics for developing and maintaining many of the YOLO models used here. They are fantastically powerful models that have been made able to run on low-power hardware like the Raspberry Pi and that is no small feat!
Appendix: Using a Webcam
This guide was built around using a Raspberry Pi camera module plugged into a CSI port. However, it is also possible to use a USB webcam as well. The code demonstrated throughout this guide should work out-of-the-box with most webcams - but with a few issues. There is a lot of variability in webcams on a Pi (which is why we opted for the camera module in this guide), but one of the common issues is a mismatched colour pallet. If the colours in your webcam feed appear to be mixed or the wrong hue, give this code a go:
import cv2
from picamera2 import Picamera2
from ultralytics import YOLO
# Initialize the Picamera2
picam2 = Picamera2()
picam2.preview_configuration.main.size = (1280, 1280)
picam2.preview_configuration.main.format = "BGR888" # Change to BGR888
picam2.preview_configuration.align()
picam2.configure("preview")
picam2.start()
# Load the YOLOv8 model
model = YOLO("yolov8s-worldv2.pt")
model.set_classes(["spray bottle"])
while True:
# Capture frame-by-frame
frame = picam2.capture_array()
# Convert BGR to RGB
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# Run YOLOv8 inference on the frame, specifying the desired size
results = model(frame_rgb, imgsz=320)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Get inference time
inference_time = results[0].speed['inference']
fps = 1000 / inference_time # Convert to milliseconds
text = f'FPS: {fps:.1f}'
# Define font and position
font = cv2.FONT_HERSHEY_SIMPLEX
text_size = cv2.getTextSize(text, font, 1, 2)[0]
text_x = annotated_frame.shape[1] - text_size[0] - 10 # 10 pixels from the right
text_y = text_size[1] + 10 # 10 pixels from the top
# Draw the text on the annotated frame
cv2.putText(annotated_frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2, cv2.LINE_AA)
# Display the resulting frame
cv2.imshow("Camera", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) == ord("q"):
break
# Close windows
cv2.destroyAllWindows()
There is no guarentee that this will work, but it should for most webcam brands. If it does, you can modify this code as needed as instructed in the guide.